What is blue-green deployment and why do we need it?

Our short story with CMS deployment
The main reasons for the change were: increased development speed, looser coupling with external dependencies, ease of customisation of the content and design, and finally, easier integration with our in-house services. Being well experienced in Java, we chose to go with Hippo CMS from OneHippo. The standard procedure for how the majority of Content Management Systems are deployed is to put up a maintenance page on a server, while the pending changes get propagated. This introduces downtime to our products which in fact disrupts user experience, provides zero high availability support and requires constant manual support. It is also important to note that Hippo CMS needs to perform many operations on the database which can take a considerable amount of time and, in the worst case, fail. All OVO Energy services are currently on Continuous Delivery with rolling releases in AWS. However, Hippo CMS is a stateful solution that limits some of our deployment choices. Therefore, instead of having night deployments or having the site unavailable for several minutes, we decided to go for blue-green strategy as the best solution.
What is blue-green deployment?
Blue-green deployment is a release methodology that decreases downtime and risk related to deployment by running two identical PRD clusters called Blue and Green. However, only one environment is live at a point in time. For example, Blue serving all production traffic, while Green is idle, or shut down to preserve resources until needed for the next release.
Before release, the idle environment can receive the new deployment, run through with service tests and be ready for going live without actually affecting the production. When ready, the DNS (ie R53) can be switched over so that all traffic is directed to the updated environment. After that, when connections are drained and no traffic comes to the old environment, it can go idle now.
What did we gain with B/G?
- Zero downtime (From hour and a half per deployment)
- Decreased risk of deploying faulty version (mainly due to extra time between deployed versions and switching DNS’s and running automated and manual testing.)
- Easy hot fixing before switching DNS if needed
- Better production risk mitigation
Under the hood
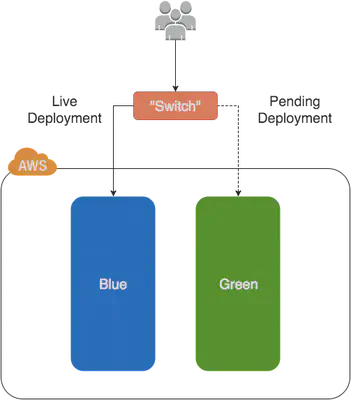
We start with servers up and running in the blue environment, as in the example above with BLUE nodes. In our case, we are running two user facing instances and one instance running with actual CMS management. On the next scheduled deployment, we fire up all instances of a green environment which contain the pending development changes. At this point, it is always good to think about data integrity. We copy the blue database (MySQL) to the green environment. Due to the previous environment being still live, we disable CMS editing changes since they would be lost after an eventual switch to the pending environment.
After successful deployment of GREEN instances, automatic testing starts with double checking the critical functionality on the pending deployed code, as well with manual testing which covers the most important parts.
DNS Switch:
On the above image, you can see Route53 from Amazon, with alias www-blue which points to ELB blue. At this point, we are happy with deployment and decide to proceed with switching the DNS’s from BLUE to GREEN load balancers.
Rundeck jobs and deployment pipeline:
Our deployment pipeline for CMS project:
1.) We build a new version of Hippo CMS with Jenkins job, change the versioning in all parts of the needed code and projects such as chef-repo, and build the chef-repo as well with Jenkins.
2.) We start the AWS instances with a Rundeck job with Blue or Green depending on schedule.
3.) In the biggest step, we run more than 10 different jobs with Rundeck ranging from stopping CMS editing to preserve data integrity copying the database to the new environment to verifying sitemaps (before and after release) and of course running automated testing with Selenium to check basic business flows.
4.) After we are happy with deployment we switch DNS.
5.) One day after deployment, after everything is working and not causing any problems, we shut down previous instances of our CMS portal and the whole accompanying infrastructure to the previous environment, which also saves a bit of money.
Tips:
1.) When using databases you must be careful regarding discrepancies between blue and green databases. One solution would be, for example, using a single database for both to preserve data integrity. But in the case of Hippo CMS, this solution would not work because content data and configuration of the CMS is stored in the same database. We disable data modification to prevent data discrepancy.
An example of discrepancies in data would be when you start the deployment and are in the middle of a deployment while changing data in the previous CMS environment(for example editor creating a new document). In this case, the data done in the previous environment would get lost. We deal with that by automatically disabling the CMS editing tool during deployment. However, the drawback of that is the downtime on the editor tool itself.
2.) It’s good to stop instances that you do not use after deployment or shortly thereafter to preserve on the price you pay for your infrastructure. Due to shutting down on demand instance we are able to offset and lower some of the costs.
3.) When switching the DNS be aware of DNS caching, and that it can delay the new instance visibility for users so it won’t be instant.
What have we learned:
Previously, when not using the blue-green releases we have had around 5 serious occurrences of downtime due to issues connected with bootstrapping new configuration changes. Having more instances also increases costs in terms of infrastructure, but thanks to using IaaS the costs can be minimised.
Moving forward, we are happy with the increase in stability and robustness regarding deployments that were achieved with moving to blue-green deployment.
References:
Matjaz Trcek
SRE @ Magnolia CMS
Working as an SRE in Magnolia CMS. In my free time I work on many side projects some of which are covered in this blog.